
Data Replication Design Spectrum
Consistent replication algorithms can be placed on a sliding scale based on how they handle replica failures. Across the three common points on this spectrum, the resource efficiency, availability, and latency are compared, providing guidance for how to choose an appropriate replication algorithm for a use case.
Failure Masking vs Failure Detection
When designing a distributed database, one needs to choose a replication algorithm to replicate data across machines. Consistent data replication algorithms fall across two categories: those designed to quietly tolerate failing replicas (failure masking), and those necessitating explicit reconfiguration around identified failures (failure detection). This post mounts the argument that these are just two opposite points on a spectrum of design possibilities in between. We’ll be taking a look at three points[1] in particular: quorum-based leaderless replication for failure masking algorithms, reconfiguration-based replication for failure detection algorithms, and leaderful consensus as the most well-known set of replication algorithms that blend the two. [1]: Don’t forget about the idea that there are more valid points along the spectrum than just these three!
There isn’t one universally optimal replication algorithm to use. Compiling together data on what replication algorithm is used by OSS, Proprietary, and internal-only Proprietary databases, we see a distribution of: [2][2]: The chart is weighted by the number of database systems, whereas a more realistic metric would be something that accounts for popularity such as the number of deployed machines or size of managed data. With cloud vendors preferring leaderful replication by a large extent, a popularity-weighted chart would likely be even more heavily skewed towards leaderful replication. However, there’s no way I can get that information to present such a graph.
Table of data from which the chart is derived
This table was assembled by
-
Reviewing https://db-engines.com/en/ranking, and looking for databases which manage their own storage (e.g. not HBase), and support consistent writes (so Cassandra is included, but CouchDB isn’t).
-
Reviewing cloud vendors for their public database offerings.
-
Looking for large companies which have internal-only databases, and reviewing their publications or blog posts.
| System | Replication Algorithm Family | Note |
|---|---|---|
MongoDB |
Leaders |
Based on Raft, per docs. |
Redis Cluster |
Leaders |
Per docs. |
Elasticsearch |
Reconfiguration |
Based off of PacificA per docs. |
Cassandra |
Quorums |
Majority quorum for most operations. LWT/Accord is leaderless consensus. |
Neo4j |
Leaders |
Raft, per docs. |
InfluxDB |
Reconfiguration |
Meta nodes run Raft. Data nodes host data. Per docs. |
CockroachDB |
Leaders |
Per docs. |
Aerospike |
Reconfiguration |
Per docs. |
Hazelcast |
Leaders |
For its CP subsystem. Per docs. |
Singlestore |
Reconfiguration |
Aggregators use Raft. Leaf nodes store data. Per docs. |
TiKV |
Leaders |
Per docs. |
ScyllaDB |
Quorums |
Per docs. |
Riak KV |
Quorums |
Per docs. |
ArangoDB |
Reconfiguration |
Agents serve as the consensus service, DB-Servers do synchronous replication within a shard. |
GraphDB |
Leaders |
Raft, per docs. |
Memgraph |
Leaders |
If I’ve understood the docs right? |
YugabyteDB |
Leaders |
Per docs. |
DGraph |
Leaders |
Per docs. |
FoundationDB |
Reconfiguration |
Per docs. |
Apache Kudu |
Leaders |
Per docs. |
Google Spanner |
Leaders |
Per docs. |
Azure CosmosDB |
Leaders |
Per docs, but they’re very not open about it. |
Alibaba PolarDB |
Leaders |
Per docs. |
Amazon DynamoDB |
Leaders |
Per paper. |
Systems such as HBase, which outsource their replication to another system (HDFS) are excluded from consideration.
So leader-based consensus, such as Raft, is indeed popular, but by no means the only valid choice. But why the differences? Why isn’t there one correct choice? What factors drove different databases to choose different solutions to their replication needs? Does Raft’s popularity correspond to its general superiority?
Different replication algorithms have different characteristics. This post breaks down each replication algorithm into its resource efficiency, availability, and latency. For resource efficiency, we’ll be looking at the question: post-replication, how much of the storage capacity and read/write throughput remains? As the counterpoints to resource efficiency, we’ll also be looking at availability (given the loss of a random machine, what’s the chance that a user will observe a transient service disruption), and latency (how many RTTs for a read or a write to complete).
With such an analysis, one would expect HN/Twitter/etc. to have replies of the form "But your analysis is invalid because you didn’t account for this replication algorithm optimization!". And so to preempt any such replies, each section produces the analysis for both the most classic, unoptimized form of the replication algorithm, and also walks through improved designs or potential optimizations that can be applied and how they affect the replication algorithm’s resource efficiency, availability, and latency. Correspondingly, this post is a sizable read. There is an excessive list of references at the bottom of this post which all link to the Google Scholar search result for each paper.
There’s also a significant scope restriction to keep this post focused and manageable. Only consistent data replication algorithms will be examined, and "consistent" always means [Linearizability] here. There are a significant number of meaningful consistency levels weaker than linearizable, however, any divergence from linearizability immediately disqualifies the algorithm or optimization from examination below. Replication algorithms with a greater focus on availability are valid and important, and an area of significant research, but have an entirely different set of trade-offs and use cases.
Lastly, this post lives purely in the land of theory. A real-life system implementing a "less efficient" replication algorithm can have higher observed resource efficiency than an implementation of a "more efficient" replication algorithm. Implementation-level choices matter tremendously. In the "write bandwidth efficiency" above, we’re only concerning ourselves with the network bandwidth. Storage efficiency partly captures the disk write bandwidth efficiency, as storing 3 copies of data requires writing 3 copies of data. However, this largely discounts the impact of storage engine write amplification, and it’s tremendously more likely that the bottleneck for writes will be the disk and not the network.[3] However, we’re discussing the theoretical write throughput trade-offs only, because write network bandwidth throughput illustrates how replication topology matters for efficiency. [3]: Storage engine write amplification tends to be anywhere from 10x-100x depending on the workload and data structure being used. Disk throughput has steadily improved over time, but disk throughput isn’t 10x-100x faster than network throughput, and thus it’s very likely the bottleneck for writes.
Failure Masking: Quorums
Replication algorithms that rely on failure masking for all of their replicas use quorums, so that a majority of replicas may make progress despite a minority of failed replicas of working replicas. The [Paxos] family of consensus protocols are well-known quorum-based replication algorithms. However, achieving consensus is not required to replicate data consistently, and simple majority quorum-based algorithms such as [ABD] are in this category. Quorum-based replication is used in industry by systems like [Megastore], [PaxosStore], and [Cassandra].
While leaderless [Paxos] and [ABD] differ in terms of consistency guarantees[4], they’re very similar in terms of resource efficiency. All replicas store a full copy of all the data. Reads and writes are broadcast to all replicas and can make forward progress with only a majority of responses. The need for a majority largely characterizes failure masking replication algorithms, as they require \(2f+1\) replicas to tolerate \(f\) failures.[5] [4]: See Murat Demirbas’s Is this consensus? for a refresher on consensus versus not. [5]: One might expect a mention of [Flexible Paxos] here, but it doesn’t change the optimal number of replicas for a given \(f\) failure tolerance. Flexible Paxos notes that \(|Q1| + |Q2| > N\) and so a minimal \(Q1\) is \(|Q1| = N - |Q2| - 1\). We require \(|Q2| = f+1\), and so for \(f=2\), that’s still \(|Q1| = 3\) and \(|Q2| = 3\).
Quorums

Our analysis is consistently targeting \(f=2\), and thus for quorums, this means we’ll be looking at the efficiencies of a replication group of \(2f+1 = 5\) replicas.
For storage efficiency, all replicas store a full copy of the data by default, and thus 1/5th of the total storage capacity is available post-replication. There are a wide set of storage optimizations, and all have seen little adoption in industry. [Witness Replicas] permit removing the full copy of the data from a minority (2/5ths) of the replication group, with that minority instead only storing the version number for each replicated value. However, this comes at the cost that a read cannot always successfully be completed if the most up-to-date value is "known" only by witnesses. This is effectively unavailability for even some types of network partitions and thus removes it from consideration for this analysis.
Erasure coding[6] is instead an attractive possibility for reducing storage costs, as it would encode the data such that any three copies could reform the original data, and the total storage used across all 5 replicas would be the equivalent of 1.67 full copies of the data. Its usual cost of having to read encoded values from three replicas to decode into the full, correct result is essentially free, as those reads are required by the quorum logic anyway. [RS-Paxos] examined applying erasure coding to Paxos log entries, and concluded that space savings can only be obtained if fault tolerance is sacrificed. However, I believe the ideas presented in [Erasure Coded Raft] should apply equally to leaderless consensus as well, so we’ll assume erasure coding is feasible.[7] HRaft adaptively changes the erasure code based on the number of available replicas, which brings the storage efficiency to 33% (a \(1+2\) code) when 3 replicas are available, to 60% storage efficiency (a \(3+2\) code) when all 5 replicas are available. Pessimistically, one must likely provision for 33% storage efficiency, but if failures can be repaired quickly, closer to the 60% storage effiency is likely. [6]: And see the Erasure Coding in Distributed Systems post on this blog. [7]: There are a number of issues being handwaved away here. It’s unclear how to apply operations from the log when any one replica only has the erasure coded values stored. [Erasure Coded Raft] falls back to full data replication when a single node stops responding, and this was improved in [Erasure Coded HRaft]. Erasure coding in consensus has not received a significant amount of academic attention, and so I’m hopeful that other deficiencies can likely be similarly explored and improved. This is mostly to show the theoretical maximum in an ideal world and less a claim that it’s what should be implemented.
Majority quorums[8] do a simple broadcast for both reads and writes, which earns a uniform 20% read bandwidth efficiency and 20% write bandwidth efficiency. Applying the erasure coding ideas above to the Paxos log entries could bring the write efficiency from 20% to 33%, and reading erasure coded data also brings the read efficiency from 20% to 33%. It is not required for majority quorums nor Paxos to always immediately send read requests to all replicas, however, and optimistically choosing to only read from a minority can allow for a read throughput of 33% when all replicas are available, at the cost of increased tail latency and degradation of latency and throughput if a replica fails. Combining this minimal majority reads with erasure coding allows for 55% read throughput efficiency. [8]: There are many ways of arranging quorums that aren’t a simple majority, and all the variations affect the read and write throughput calculations. It used to be more popular to allow for tuning the read quorum and write quorum sizes, but many of those systems have since died out, such as Riak. More esoteric quorum setups exist, but they aren’t commonly used and thus out of scope for this post. [Quoracle] is a fun read on alternative schemes though.
A major advantage of leaderless, quorum-based algorithms is the lack of dependence on a leader. All failures can be masked, with no need to detect or reconfigure around the failure. All leaderless replication algorithms earn a perfect 0% chance of unavailability on random node failure.
Though majority quorums has been repetitively stated to be a simple 1RTT broadcast for both reads and writes, that’s a bit of an oversimplification. For majority quorums to be linearizable, this post’s threshold for "consistent", [Read Repair] must be used to write back the most recent value if replicas diverged, thus earning a worst-case 2RTT for reads. Majority quorums are thus the inverse of Paxos, which always has two rounds of broadcasts for writes, and reads are a one-round broadcast. [FastPaxos] permits performing writes in one-round if a supermajority of replicas accept.
An implementation of majority quorums typically uses some form of a Last Writer Wins timestamping scheme, so that if a read returns three distinct values, it’s possible to choose the "most recent" value as the correct read result. [ABD] uses a logical clock, and what’s referred to as just "majority quorums"[9] here uses a physical clock. ABD ensures that its writes have a higher logical clock than all existing values by first reading the existing values, thus earning it 2RTT for writes, and does a similar read repair step after reads to earn it 2RTT for reads also. Majority quorums with physical timestamping can use its local time to skip the first phase of ABD’s write protocol, so its writes are just 1RTT. [9]: If it were not for the immense popularity of physically timestamped majority quorums, due to its use in systems like Cassandra, I would have greatly preferred to present ABD as the "default" majority quorum algorithm. For learning purposes, at least I’d suggest starting with it instead.
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
Majority Quorums |
20% |
20% |
20% |
0 |
2RTT |
1RTT |
ABD |
20% |
20% |
20% |
0% |
2RTT |
2RTT |
Paxos |
20% |
20% |
20% |
0% |
1RTT |
2RTT |
Minimal Majority Reads Paxos |
20% |
33% |
20% |
0% |
1-2RTT |
2RTT |
20% |
20% |
20% |
0% |
1RTT |
1-2RTT |
|
Erasure Coded Paxos |
33% - 60% |
33% |
33% |
0% |
1RTT |
2RTT |
Erasure Coded Minimal Majority Reads Paxos |
33% - 60% |
55% |
33% |
0% |
1-2RTT |
2RTT |
This table presents that the difference between majority quorums/ABD and Paxos is one of read and write latency, but again, don’t forget that there’s a very significant difference in data consistency between the two replication algorithms. It’s also not strictly a one-or-the-other. [Gryff] is an example of a design uses [ABD] for reads and writes, and [EPaxos] for read-modify-writes. Although Erasure Coded Paxos outwardly appears optimal across several metrics, it isn’t an algorithm that actually exists neither in academia nor in industry.
One of the largest concerns around deploying [Paxos] to production is its vulnerability to livelock under contention. Contending proposals can force both to retry the writes, mutually preventing forward progress, and so contention on a single replicated item is to be avoided if possible. [Megastore] is very contention prone as every proposal is trying to target the next slot in the replicated log, and thus they tried to include a weak leadership optimization. [PaxosStore] deployed only to geographically close replicas to minimize the latency from proposing to accepting, thus minimizing the window for proposals to conflict. [EPaxos] focuses on allowing concurrent updates to distinct entities, and only ordering conflicting proposals. [CASPaxos] avoids a log entirely, and thus trivially allows concurrent updates on distinct items. [Tempo] and [Accord] assign client-generated timestamps to all requests so that all replicas process requests in a deterministic order, but at the cost of a fixed increase in latency to wait out clock skew bounds before processing any request. If a use case requires handling potentially many concurrent update attempts to the same item, then it’s possible that leaderless consensus is not a good choice of replication algorithm.
Failure Detection: Reconfiguration
Failure detection-based replication algorithms have a chosen set of replicas in a replication group which must be live for the algorithm to make progress. On detected replica failure, these algorithms reconfigure the replication group to exclude the failed replica and include a new, live replica. Rather than allow replicas to be failed, a failed replica is evicted from the replication group. All replicas are either working, or will be removed.
All reconfiguration-based replication protocols share certain attributes. All writes are always sent to all replicas, and a single replica will always have a full and consistent snapshot of the replicated data. This means reads may be served by a single replica. Additionally, only \(f+1\) replicas are needed to tolerate \(f\) failures, as the one remaining replica will be sufficient to re-replicate the data. However, due to only having \(f+1\) replicas, there is a consistent theme in that all algorithms examined are not consensus. This also means that they cannot solve consensus problems, such as deciding which replicas are responsible for a shard of data, or which node is the primary. They all rely on an external consensus service to help with those issues. Think of this as a control plane / data plane split: there’s one instance of a consensus service in the control plane orchestrating the small amount of metadata deciding which replicas are in which replication groups responsible for which shards of data, and the horizontally scalable data plane replicates each shard of data within its assigned group.
There are two shapes of algorithms in this class of failure detection-based replication protocols: those in which inter-replica communication is done as a broadcast, and those in which it is done as a linear chain. Broadcast-based replication is well known as [Primary-Backup][10] replication, which we’ll be examining through the lens of [PacificA] which has more of an emphasis on the reconfiguration support, and [Hermes] as a more recent improvement on broadcast-based replication. For chain-based replication, we’ll be examining the original [Chain Replication], and [CRAQ] as its more recent improvement. [10]: Some implementations of primary-backup do asynchronous replication to all replicas, and those are excluded from consideration in this entire post because it’s not consistent replication. Some implementations of primary-backup allow waiting for a subset, but not all, of the backups to acknowledge a write from the primary, and this is excluded from consideration in this section because that’s failure masking for backups! Specifically, that’s a Hybrid replication algorithm, which is examined in the section below. Only fully synchronous primary-backup replication is in scope for this section.
In academia, many of the ideas in reconfiguration-based replication are rooted in [Virtual Synchrony]. Evolving Paxos into a reconfigurable primary-backup replication was examined in [Vertical Paxos II]. In industry, [Kafka] and [FoundationDB] use different variants of broadcast-based replication, and Apache Pegasus uses [PacificA]. Nearly all of the chain replication databases in industry seem to have died out, as hibari was one of the last but appears abandoned now, and [HyperDex] almost become a startup. Reconfiguration-based replication algorithms are frequently found in block and blob storage products[11] where the decreased number of replicas means significant cost savings. [Ceph] implements both broadcast and chain-based replication. [GFS] implements broadcast-based replication, and [HDFS] similarly follows suit. [11]: That’s not to say that all such storage products do, as for example [Alibaba EFS] and [PolarFS] use leaderful consensus, but just that reconfiguration-based replication is comparatively a much more frequently chosen solution for replication in the different domain. It’s databases specifically that are more aligned around leaderful consensus.

Our analysis is consistently targeting \(f=2\), and thus for quorums, this means we’ll be looking at the efficiencies of a replication group of \(f+1 = 3\) replicas.
In reconfiguration-based replication algorithms, all three replicas store a full copy of the data, yielding a 33% storage efficiency for all four algorithms. Unlike the quorum systems, there’s no inherent opportunity for erasure coding. When the number of replicas is \(f+1\), we expect that a single alive replica can serve reads for all of its data. Applying erasure coding requires increasing the set of replicas (while the erasure coding maintains the same aggregate storage efficiency), and then choosing the number of parity blocks to equal the number of failures one wishes to be able to recover from. This effectively applies quorums for failure masking, though at the level of erasure coding rather than at the level of the replication algorithm. Such a design is common in blob storage systems, but not in distributed databases, except for YDB.
With [Chain Replication], only the tail of the chain is allowed to answer read requests, which it does with 1RTT means a read bandwidth efficiency of 33%. [CRAQ] permits any node to answer reads, and thus it gets 100% read bandwidth efficiency, but if there’s an ongoing write to the same key, the replica has to wait to hear back from the tail replica that the write was completed before it may respond to the read.[12] Both [PacificA] and [Hermes] are capable of serving reads from all replicas, so they gain a 100% read bandwidth efficiency. [PacificA]'s primary can serve reads in 1RTT and the secondaries in 2RTT (as they must check with the primary). [Hermes] allows serving reads in 1RTT (but possibly requires waiting for up to 1RTT while a write finishes). If we wished to strictly ensure 1RTT reads, one could use [PacificA] and decline to read from the secondaries. [12]: This means CRAQ is optimal for 100% read or 100% write workloads, and degrades read latency in between, which is a trade off I haven’t seen in any other replication algorithm. It’d be ideal for large data loads (100% writes), followed by an online serving workload (100% reads), and could serve reads with degraded latency as a data load is ongoing.
Both [Chain Replication] and [CRAQ] have 33% write bandwidth efficiency, as one replica accepts writes and each replica sends to only one more replica so there’s no further bottleneck on outgoing bandwidth. The chain means that writes in both take 2.5RTT to complete[13]. [PacificA] only allows the primary to accept writes, and it must broadcast to two replicas, yielding a 16% write bandwidth efficiency. [Hermes] allows any replica to accept writes, and receives the replication broadcast from the other two replicas. This balances the incoming and outgoing bandwidth requirements to allow 33% write bandwidth efficiency. Both broadcast-based replication algorithms take 2RTT for writes. [13]: 2.5RTT assumes that when a write reaches the tail, the ack is set to the head, which is then sent to the client. A tail node could reply directly to the client, but that breaks most RPC models. [Chain Replication] itself is ambiguous on the intended behavior, but this mode is also assumed in [Throughput Optimal Broadcast].
Unavailability is the weak point of reconfiguration-based systems. In all examined systems, any failure requires detection (generally through a heartbeat timeout), and then a membership view change to a new set of non-failed replicas. Any replica failure has a 100% chance of causing a client-visible spike in latency due to no requests being processed while the heartbeat times out and the view change protocol runs.
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
33% |
33% |
33% |
100% |
1RTT |
2.5RTT |
|
33% |
100% |
33% |
100% |
1-3RTT |
2.5RTT |
|
33% |
100% |
16.7% |
100% |
1-2RTT |
2RTT |
|
[PacificA] (Primary-only) |
33% |
33% |
16.7% |
100% |
1RTT |
2RTT |
33% |
100% |
33% |
100% |
1-2RTT |
2RTT |
The end result shows that [CRAQ] is a better version of [Chain Replication], and [Hermes] is a better version of [PacificA]. To optimize for latency, choose [Hermes]. To optimize for throughput, choose [CRAQ].
It’s important to note that the surface-level simplicity of replication algorithms rooted in [Virtual Synchrony] instead hold their complexity in two nontrivial topics: group membership and failure detection.
The focus on how to change a replication group’s members is not unique to reconfiguration-based protocols. There’s nice tutorial papers focusing on reconfiguration both for consensus-based state machines in [Reconfiguring a State Machine] and for the weaker atomic storage model, see [Reconfiguring Replicated Storage Tutorial] which uses [ABD] as its example protocol. [Viewstamped Replication] directly models leader election as a reconfiguration. However, reconfiguration-based replication algorithms are unique in that they use reconfiguration as their only way to handle replica failures. An external service being the authority on what replicas are or are not part of a given replication group adds an additional layer of complexity that isn’t present in consensus systems. [PacificA] has a great discussion of this topic.
Failure detectors have their own rich history that warrants a separate post sometime. The simplest failure detector is a periodic heartbeat with a timeout. An ideal failure detector is both accurate in detecting when a component has failed, and reactive in minimizing the time between the failure and the detector identifying it. [Localizing Partial Failures] pitches specializing failure detection to each individual component/behavior/RPC endpoint of a system. [Falcon] presents a compelling argument that involving of multiple layers of a system can provide a faster reaction to failures than heartbeats alone. The best failure detection is likely to be tightly integrated with both the service being monitored and the environment the service runs in.
Furthermore, failure detection is not just for crash-stop failures. One needs a very precise definition of what "functioning correctly" means. If the disk is failing and its throughput drops by 90% or if there’s a bad switch causing packet loss and thus TCP throughput drops significantly[14], that’s not a "correctly functioning" machine, and one would wish to reconfigure around the failure. [Gray Failure Achilles Heel] discusses gray failure issues in more detail. [Limping Hardware Tolerant Clouds] offers more concrete examples. Dan Luu has written about this as well. Detecting "slow" is significantly more difficult than detecting "failed", with an approach to doing so illustrated in [Perseus]. [14]: The most frequent singular cause of times I’ve been paged awake by a service in the middle of the night has been some networking equipment deciding to drop 1% of packets, and TCP thus slowing down to approximately dial-up speeds. Heartbeats could still be sent, so the service wasn’t "unavailable", but it sure wasn’t working well.
Hybrid: Leaders
Leaderful consensus is what is generally brought to mind when one mentions "consensus". It is best known as [Raft], [MultiPaxos][15] or [ZAB], and exemplified by distributed databases such as [CockroachDB], [TiDB] and [Spanner], or configuration management systems such as [Paxos Made Live] and [Zookeeper]. (Among many other high-quality, production systems.) [15]: Though for learning about Multi-Paxos, I’d significantly recommend reading [Paxos Made Moderately Complex] and [MultiPaxos Made Complete] instead.
In the simplest Raft implementation, one replica is nominated as a leader. All operations are sent to the leader, and the leader broadcasts the replication stream to its followers. Raft tolerates \(f\) failures using \(2f+1\) replicas. Thus, at most two of five replicas are permitted to be unavailable. Throughout this section, I will be using "Raft" and "Multi-Paxos" interchangeably. The differences between the two algorithms (discussed in detail in [Paxos vs Raft]) do not affect resource efficiency, throughput or latency.
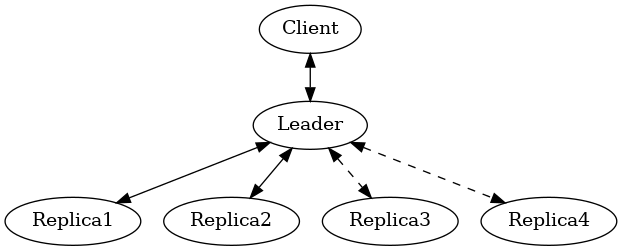
Our analysis is consistently targeting \(f=2\), and thus for quorums, this means we’ll be looking at the efficiencies of a replication group of \(2f+1 = 5\) replicas.
All replicas store a full copy of the data, and thus 1/5th of the total storage capacity is available post-replication. The storage optimizations available are similar to what was discussed for leaderless replication. [Witness Replicas] permit removing the full copy of the data from a minority (2/5ths) of the replication group, and the leaderful consensus variant of witness replicas is always able to serve reads from the leader even with a simple majority of replicas alive. Note though, that removing storage means that witness replicas can’t serve reads. I’m only aware of EnterpriseDB Postgres Distributed and (Cloud) Spanner implementing support for witness replicas as part of Raft and Multi-Paxos, respectively. The other possible direction for storage efficiency improvement is [Erasure Coded Raft] which again allows between a 33% and 60% storage efficiency depending on replica availability. As 99% of the Raft implementations one might ever encounter have a storage efficiency of 1/5th, that is the value that will be used for storage efficiency for the rest of the analysis.
Naive Raft has the leader serve all reads, yielding 1/5th read throughput at 1RTT[16]. [Linearizable Quorum Reads] pitches the idea that one can also perform linearizable reads by reading from a majority quorum of the non-leader replicas, and implementing this brings Raft to 2/5ths read throughput (1/5th from the leader + 1/5th aggregate across the followers). [Paxos Quorum Leases][17] pitches the idea of electing a leader and two more replicas to which the leader must replicate all commits, thus enabling those required followers to serve reads to clients with no further coordination, which brings Raft to 3/5ths read throughput (1/5th for each leader and lease holder) at the cost of some tail latency on writes and increased risk of unavailability on failure. [Consistent Follower Reads][18][19] allows any follower to serve read requests by first checking with the leader for the most recently applied position in the replication log, allowing for 5/5ths read throughput at the cost of read latency increasing to 2RTTs. [Ionia] introduces an optimistic protocol which concurrently queries a follower for the data and the leader for the freshness, that permits 1RTT reads from followers although it suffers unbounded retry attempts on frequently modified data. Each has their own set of trade-offs, but we’ll use 5/5ths as Raft’s optimal read throughput, which is realistic given that follower reads have been implemented in production systems such as Spanner and TiKV. [16]: Leaders may not trivially serve read requests, otherwise, no-longer leaders risk serving stale results. Leaders must either wait for the next quorum reply to confirm leadership, or use time-based leader leases to exclude potential concurrent leaders. We assume the latter, as it is commonly implemented. [17]: [Paxos Quorum Leases] is an example of a replication algorithm that’s a hybrid of failure masking and failure detection, but strikes a trade-off more towards failure detection than where Raft sits. [18]: "Follower reads" can be colloquially used to mean any form of reading from followers. Cockroach in particular uses a number of tricks around timestamps to allow replicas to locally serve data. What they call follower reads allows replicas to serve reads for older versions. Global tables support local, consistent reads by writing in the future. My focus is specifically on linearizable reads which don’t overly compromise writes, and that specific cockroach feature isn’t yet implemented. But I highlight all of this to show that there’s ways to deliver increased read throughput when bending other constraints or leaning on the semantics of other components (e.g. hybrid clocks). [19]: [Consistent Follower Reads] has superseded the other citable works for follower reads. [Raft’s Consistent Follower Reads] has a mention of the optimization in passing. PingCAP’s blog post on implementing it is a more detailed overview.
In classic Raft, all proposals go to the leader, and then the leader broadcasts the proposals to all followers. This means Raft is first constraining to utilizing only \(1/(2f+1)\) or 1/5th of the available incoming bandwidth. Then the bottleneck becomes the leader’s outgoing bandwidth, further reduction of \(1/2f\), so 1/4th. This means a write bandwidth efficiency of \(1/(4f^2 + 2f)\) or 1/20th. There have been ways discussed to scale the write bandwidth. [Pull-Based Consensus] presents an argument that a fixed topology is not needed, replicas can fetch from other replicas, and thus even a linear chain of replicas could work. [Scaling Replication] shows another view that the work of broadcasting to all replicas can be delegated to other replicas. [Commutative Raft] presents a different approach, in which clients are allowed to directly send to all replicas (avoiding the leader bottleneck), and the leader only arbitrates ordering when there are conflicts (and saving 1RTT when there aren’t). Of these, only [Pull-Based Consensus] is implemented in industry, but I’m not aware that even MongoDB itself runs in a linear chain configuration. (It’s mostly about saving WAN costs.) [Erasure Coded Raft] applies to the Raft log as well, providing a 5/3rds increase in bandwidth. However, 1/20th is still the write bandwidth efficiency that almost any real Raft implementation will exhibit.
Many optimizations strike different points along the Pareto curve of latency versus throughput, so I’ve outlined them all below. Combinations of them form the optimal trade-offs for latency or throughput, so I’ll also note a "Latency Optimized Raft" as [Linearizable Quorum Reads] + [Commutative Raft], and a "Throughput Optimized Raft" implementation as the effect of combining [Consistent Follower Reads], [Pull-Based Consensus] in a linear chain of replicas, and [Erasure Coded Raft].
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
Simplest |
20% |
20% |
5% |
20% |
1RTT |
2RTT |
20% |
40% |
5% |
20% |
1RTT |
2RTT |
|
20% |
20% |
20% |
20% |
1RTT |
1-2RTT |
|
Latency Optimal Raft |
20% |
40% |
20% |
20% |
1RTT |
1-2RTT |
20% |
60% |
5% |
60% |
1RTT |
2RTT |
|
20% |
100% |
5% |
20% |
1-2RTT |
2RTT |
|
33% - 60% |
20% |
8.3% |
20% |
2RTT |
2RTT |
|
Throughput Optimized Raft |
33% - 60% |
100% |
33% |
20% |
2RTT |
3.5RTT |
Databases built around Multi-Paxos generally aren’t picking just one optimization to implement. The exact tradeoff of reads versus writes and throughput versus latency is specific to each individual use case. Thus, databases tend to implement multiple optimizations and allow users to configure specific database deployments or tables within the database for how they wish for reads and writes to be done. The optimizations covered above are also just those that affect resource efficiency. There’s a tremendously larger set of published optimizations focusing on performance when geographically distributed, enhancing failure recovery, managing replicated log truncation, etc.
In the failure detection section, we discussed the complexity of failure detection-based replication algorithms is often centered around group membership changes and (gray) failure detectors. Safe group membership changes is a topic occasionally discussed in consensus papers. Heidi Howard’s distributed consensus reading list has a whole section on it. Comparatively, the need for a comprehensive failure detector for the Raft leader is often overlooked. Notably, however, [MultiPaxos Made Complete] gives the topic a proper treatment.
One of the major points of this post is that a five replica Raft group is 1/5th failure detection + 4/5ths failure masking. However you feel about reconfiguration and failure detection-based distributed system design is exactly how you should feel about the leader in Raft/Multi-Paxos. Some folk really don’t like systems that rely on failure detectors and have a reconfiguration step during which the partition is unavailable, and that’s okay. But any failure pattern you might have thought of and felt concerned about while reading the failure detection section applies precisely the same to the leader in Raft. If it seems unacceptable that chain replication has unavailability during reconfiguration when any replica fails, the exact same unavailability during reconfiguration happening to Raft when the leader fails should also feel unacceptable.
Comparison
There isn’t a single way to do a direct, fair, apples-to-apples comparison of different systems and optimizations across the different replication algorithms. We’ll first look at the most popular/common choice for each category, and then take a look at the latency-optimal, throughput-optimal, and storage-optimal choices.
For the popularity-based rankings, we’ll use "Paxos" from the Quorums section, "PacificA" from the Reconfiguration section, and "Consistent Follower Reads" from the Hybrid section:
Replicas Required for \(f=2\) |
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
Paxos |
5 |
20% |
20% |
20% |
0% |
1RTT |
2RTT |
PacificA |
3 |
33% |
100% |
16.7% |
100% |
1-2RTT |
2RTT |
Follower Reads |
5 |
20% |
100% |
5% |
20% |
1-2RTT |
2RTT |
Using Paxos requires compromising read throughput. PacificA delivers superior write bandwidth and similar latencies to Raft, with the trade-off being a higher chance of unavailability versus more replicas required, respectively.
For our latency-optimized comparison, "Fast Paxos" is the quorum-based replication algorithm which offers the possibility for 1RTT reads and writes. "PacificA (Primary-only)" is the latency optimal reconfiguration-based algorithm. Linearizable Quorum Reads is our hybrid selection. (And note again that all primary/leader-based replication algorithms depend on leader leases and clock synchronization to be able to serve 1RTT reads from the primary/leader.)
Replicas Required for \(f=2\) |
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
Fast Paxos |
5 |
20% |
20% |
20% |
0% |
1RTT |
1-2RTT |
PacificA Primary-Only |
3 |
33% |
33% |
33% |
100% |
1RTT |
2RTT |
Latency Optimized Raft |
5 |
20% |
40% |
20% |
20% |
1RTT |
1-2RTT |
Reveals an interesting effect that Reconfiguration-based algorithms have lower read throughput on the lowest latency variant than either quorum-based or hybrid replication schemes.[20] [20]: I don’t think a similar optimization which reads only from the backups would be safe unless commits were made durable on the primary first before replication, which would likely cost more than an extra write RTT. Would be happy to find out I’m wrong!
For our throughput-optimized and storage-optimized variant analysis, our choices are actually the same! It’s the erasure coded variant of each replication algorithm. (Except for storage-optimized reconfiguration-based replication algorithm, we could arbitrarily choose any, as they’re all the same, but CRAQ is the correct choice for throughput-optimized.)
Replicas Required for \(f=2\) |
Storage Efficiency |
Read Bandwidth Efficiency |
Write Bandwidth Efficiency |
Chance of Unavailability on Failure |
Read Latency |
Write Latency |
|
Erasure Coded Minimal Majority Reads Paxos |
5 |
33% |
55% |
33% |
0% |
1RTT |
2RTT |
CRAQ |
3 |
33% |
100% |
33% |
100% |
1-3RTT |
2.5RTT |
Erasure Coded CRAQ |
5 |
60% |
100% |
20% |
100% |
1-5RTT |
3.5RTT |
Throughput Optimized Raft |
5 |
33% - 60% |
100% |
33% |
20% |
2RTT |
3.5RTT |
We see that erasure coding just brings each quorum-based algorithm to the resource efficacy of the reconfiguration-based algorithm in its worst case, but still requires 66% more replicas than a reconfiguration-based algorithm. A 5-replica erasure coded variant of CRAQ permits always being able to obtain the 60% storage efficiency. This leaves reconfiguration-based replication algorithms and Throughput Optimized Raft as the most cost-effective to deploy for use cases bottlenecked on storage or throughput. Throughput Optimized Raft gives a lower chance of unavailability on failure, whereas reconfiguration-based replication is significantly less complex to implement and has a lower minimum number of replicas.
There are a number of other resources to consider in a real environment other than what was presented in this post. CPU, memory, disk IOPS, etc., are all finite resources, which were not discussed, but if those become the limiting factor for performance, then that is the bottleneck and efficiency metric to be mindful of. As one example, [Scalable But Wasteful] notes that constrained CPU usage can lead [MultiPaxos] (and probably [PacificA]) to have 2x more throughput than [EPaxos]. If throughput is what determines the amount of hardware you need to buy/rent for your database deployment, and the hardware is CPU constrained, then this is a more impactful efficiency to keep in mind than anything discussed above.
There are also other deployment environment considerations. The analysis above considers all round-trip times equal, which is not the case in geographically distributed deployments. Cross-datacenter network links are notoriously prone to random packet delays or loss, making any form of quorums more attractive for minimizing tail latency. All RTT calculations above have considered a request as starting from a client, but if a client is always co-located with the primary or leader in a datacenter, that RTT is comparatively free, and only the round trips across datacenters or regions are worth optimizing. One should tailor the choice of replication algorithm to also best suit the deployment environment.
But after all this analysis, does Raft’s hybrid approach to failure handling deliver some superior advantage that justifies its popularity? Not really. Quorums deliver superior availability, but at the cost of read throughput efficiency (and livelock for Paxos, or inconsistency for ABD). Reconfiguration delivers superior resource efficiency, but at the cost of availability. Raft has unwaveringly moderate results in each comparison. Instead, its main strength is that its hybrid nature avoids the major pitfalls on both sides: it won’t livelock under contention, and it can mask some failures. If those are what the use case needs, then it’s a great fit. Otherwise, consider implementing a different approach.
See Also
-
Adam Prout has a post on Categorizing How Distributed Databases Utilize Consensus Algorithms which presents Quorums and Hybrid as "Consensus for Data (CfD)" and Reconfiguration as "Consensus for Metadata (CfM)".
References
-
[Linearizability] Maurice P. Herlihy and Jeannette M. Wing. 1990. Linearizability: a correctness condition for concurrent objects. ACM Trans. Program. Lang. Syst. 12, 3 (July 1990), 463–492. [scholar]
-
[Paxos] Leslie Lamport. 2001. Paxos Made Simple. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) (December 2001), 51–58. [scholar]
-
[ABD] Hagit Attiya, Amotz Bar-Noy, and Danny Dolev. 1995. Sharing memory robustly in message-passing systems. J. ACM 42, 1 (January 1995), 124–142. [scholar]
-
[Megastore] Jason Baker, Chris Bond, James C. Corbett, JJ Furman, Andrey Khorlin, James Larson, Jean-Michel Leon, Yawei Li, Alexander Lloyd, and Vadim Yushprakh. 2011. Megastore: Providing Scalable, Highly Available Storage for Interactive Services. In Proceedings of the Conference on Innovative Data system Research (CIDR), 223–234. [scholar]
-
[PaxosStore] Jianjun Zheng, Qian Lin, Jiatao Xu, Cheng Wei, Chuwei Zeng, Pingan Yang, and Yunfan Zhang. 2017. PaxosStore: high-availability storage made practical in WeChat. Proc. VLDB Endow. 10, 12 (August 2017), 1730–1741. [scholar]
-
[Cassandra] Avinash Lakshman and Prashant Malik. 2010. Cassandra: a decentralized structured storage system. SIGOPS Oper. Syst. Rev. 44, 2 (April 2010), 35–40. [scholar]
-
[Flexible Paxos] Heidi Howard, Aleksey Charapko, and Richard Mortier. 2021. Fast Flexible Paxos: Relaxing Quorum Intersection for Fast Paxos. In Proceedings of the 22nd International Conference on Distributed Computing and Networking (ICDCN '21), Association for Computing Machinery, New York, NY, USA, 186–190. [scholar]
-
[Witness Replicas] Jehan-Francois Paris. 1990. Efficient voting protocols with witnesses. In ICDT '90, Springer Berlin Heidelberg, Berlin, Heidelberg, 305–317. [scholar]
-
[RS-Paxos] Shuai Mu, Kang Chen, Yongwei Wu, and Weimin Zheng. 2014. When paxos meets erasure code: reduce network and storage cost in state machine replication. In Proceedings of the 23rd International Symposium on High-Performance Parallel and Distributed Computing (HPDC '14), Association for Computing Machinery, New York, NY, USA, 61–72. [scholar]
-
[Erasure Coded Raft] Zizhong Wang, Tongliang Li, Haixia Wang, Airan Shao, Yunren Bai, Shangming Cai, Zihan Xu, and Dongsheng Wang. 2020. CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost. In 18th USENIX Conference on File and Storage Technologies (FAST 20), USENIX Association, Santa Clara, CA, 297–308. [scholar]
-
[Erasure Coded HRaft] Yulei Jia, Guangping Xu, Chi Wan Sung, Salwa Mostafa, and Yulei Wu. 2022. HRaft: Adaptive Erasure Coded Data Maintenance for Consensus in Distributed Networks. In 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 1316–1326. [scholar]
-
[Quoracle] Michael Whittaker, Aleksey Charapko, Joseph M. Hellerstein, Heidi Howard, and Ion Stoica. 2021. Read-Write Quorum Systems Made Practical. In Proceedings of the 8th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC '21), Association for Computing Machinery, New York, NY, USA. [scholar]
-
[Read Repair] D. Malkhi and M.K. Reiter. 1998. Secure and scalable replication in Phalanx. In Proceedings Seventeenth IEEE Symposium on Reliable Distributed Systems (Cat. No.98CB36281), 51–58. [scholar]
-
[FastPaxos] Leslie Lamport. 2006. Fast Paxos. Distributed Computing 19, 2 (October 2006), 79–103. [scholar]
-
[Gryff] Matthew Burke, Audrey Cheng, and Wyatt Lloyd. 2020. Gryff: Unifying Consensus and Shared Registers . In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), USENIX Association, Santa Clara, CA, 591–617. [scholar]
-
[EPaxos] Iulian Moraru, David G. Andersen, and Michael Kaminsky. 2013. There is more consensus in Egalitarian parliaments. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP '13), Association for Computing Machinery, New York, NY, USA, 358–372. [scholar]
-
[CASPaxos] Denis Rystsov. 2018. CASPaxos: Replicated State Machines without logs. [scholar] [arXiv]
-
[Tempo] Vitor Enes, Carlos Baquero, Alexey Gotsman, and Pierre Sutra. 2021. Efficient replication via timestamp stability. In Proceedings of the Sixteenth European Conference on Computer Systems (EuroSys '21), Association for Computing Machinery, New York, NY, USA, 178–193. [scholar] [arXiv]
-
[Accord] Elliott Smith Benedict, Tony Zhang, Blake Eggleston, and Scott Andreas. 2021. CEP-15: Fast General Purpose Transactions. Retrieved from https://cwiki.apache.org/confluence/download/attachments/188744725/Accord.pdf
-
[Primary-Backup] Navin Budhiraja. 1993. The primary-backup approach: lower and upper bounds. PhD thesis. Cornell University, USA. UMI Order No. GAX94-06131. [scholar]
-
[PacificA] Wei Lin, Mao Yang, Lintao Zhang, and Lidong Zhou. 2008. PacificA: Replication in Log-Based Distributed Storage Systems. [scholar]
-
[Hermes] Antonios Katsarakis, Vasilis Gavrielatos, M.R. Siavash Katebzadeh, Arpit Joshi, Aleksandar Dragojevic, Boris Grot, and Vijay Nagarajan. 2020. Hermes: A Fast, Fault-Tolerant and Linearizable Replication Protocol. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '20), Association for Computing Machinery, New York, NY, USA, 201–217. [scholar]
-
[Chain Replication] Robbert Van Renesse and Fred B. Schneider. 2004. Chain Replication for Supporting High Throughput and Availability. In 6th Symposium on Operating Systems Design & Implementation (OSDI 04), USENIX Association, San Francisco, CA. [scholar]
-
[CRAQ] Jeff Terrace and Michael J. Freedman. 2009. Object Storage on CRAQ: High-Throughput Chain Replication for Read-Mostly Workloads. In 2009 USENIX Annual Technical Conference (USENIX ATC 09), USENIX Association, San Diego, CA. [scholar]
-
[Virtual Synchrony] K. Birman and T. Joseph. 1987. Exploiting virtual synchrony in distributed systems. In Proceedings of the Eleventh ACM Symposium on Operating Systems Principles (SOSP '87), Association for Computing Machinery, New York, NY, USA, 123–138. [scholar]
-
[Vertical Paxos II] Leslie Lamport, Dahlia Malkhi, and Lidong Zhou. 2009. Vertical Paxos and Primary-Backup Replication. Microsoft. [scholar]
-
[Kafka] Jay Kreps, Neha Narkhede, Jun Rao, and others. 2011. Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB, Athens, Greece, 1–7. [scholar]
-
[FoundationDB] Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. 2021. FoundationDB: A Distributed Unbundled Transactional Key Value Store. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD '21), Association for Computing Machinery, New York, NY, USA, 2653–2666. [scholar]
-
[HyperDex] Robert Escriva, Bernard Wong, and Emin Gun Sirer. 2012. HyperDex: a distributed, searchable key-value store. In Proceedings of the ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM '12), Association for Computing Machinery, New York, NY, USA, 25–36. [scholar]
-
[Ceph] Sage A. Weil, Andrew W. Leung, Scott A. Brandt, and Carlos Maltzahn. 2007. RADOS: a scalable, reliable storage service for petabyte-scale storage clusters. In Proceedings of the 2nd International Workshop on Petascale Data Storage: Held in Conjunction with Supercomputing '07 (PDSW '07), Association for Computing Machinery, New York, NY, USA, 35–44. [scholar]
-
[GFS] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google file system. SIGOPS Oper. Syst. Rev. 37, 5 (October 2003), 29–43. [scholar]
-
[HDFS] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler. 2010. The Hadoop Distributed File System. In 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 1–10. [scholar]
-
[Alibaba EFS] Weidong Zhang, Erci Xu, Qiuping Wang, Xiaolu Zhang, Yuesheng Gu, Zhenwei Lu, Tao Ouyang, Guanqun Dai, Wenwen Peng, Zhe Xu, Shuo Zhang, Dong Wu, Yilei Peng, Tianyun Wang, Haoran Zhang, Jiasheng Wang, Wenyuan Yan, Yuanyuan Dong, Wenhui Yao, Zhongjie Wu, Lingjun Zhu, Chao Shi, Yinhu Wang, Rong Liu, Junping Wu, Jiaji Zhu, and Jiesheng Wu. 2024. What’s the Story in EBS Glory: Evolutions and Lessons in Building Cloud Block Store. In 22nd USENIX Conference on File and Storage Technologies (FAST 24), USENIX Association, Santa Clara, CA, 277–291. [scholar]
-
[PolarFS] Wei Cao, Zhenjun Liu, Peng Wang, Sen Chen, Caifeng Zhu, Song Zheng, Yuhui Wang, and Guoqing Ma. 2018. PolarFS: an ultra-low latency and failure resilient distributed file system for shared storage cloud database. Proc. VLDB Endow. 11, 12 (August 2018), 1849–1862. [scholar]
-
[Throughput Optimal Broadcast] Rachid Guerraoui, Ron R. Levy, Bastian Pochon, and Vivien Qu'ema. 2010. Throughput optimal total order broadcast for cluster environments. ACM Trans. Comput. Syst. 28, 2 (July 2010). [scholar]
-
[Reconfiguring a State Machine] Leslie Lamport, Dahlia Malkhi, and Lidong Zhou. 2010. Reconfiguring a state machine. SIGACT News 41, 1 (March 2010), 63–73. [scholar]
-
[Reconfiguring Replicated Storage Tutorial] Marcos K. Aguilera, Idit Keidar, Dahlia Malkhi, Jean-Philippe Martin, and Alexander Shraer. 2010. Reconfiguring Replicated Atomic Storage: A Tutorial. Bulletin of the EATCS: The Distributed Computing Column (October 2010). [scholar]
-
[Viewstamped Replication] Barbara Liskov and James Cowling. 2012. Viewstamped Replication Revisited. MIT. [scholar]
-
[Localizing Partial Failures] Chang Lou, Peng Huang, and Scott Smith. 2020. Understanding, Detecting and Localizing Partial Failures in Large System Software . In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), USENIX Association, Santa Clara, CA, 559–574. [scholar]
-
[Falcon] Joshua B. Leners, Hao Wu, Wei-Lun Hung, Marcos K. Aguilera, and Michael Walfish. 2011. Detecting failures in distributed systems with the Falcon spy network. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles (SOSP '11), Association for Computing Machinery, New York, NY, USA, 279–294. [scholar]
-
[Gray Failure Achilles Heel] Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. 2017. Gray Failure: The Achilles' Heel of Cloud-Scale Systems. In Proceedings of the 16th Workshop on Hot Topics in Operating Systems (HotOS '17), Association for Computing Machinery, New York, NY, USA, 150–155. [scholar]
-
[Limping Hardware Tolerant Clouds] Thanh Do and Haryadi S. Gunawi. 2013. The Case for Limping-Hardware Tolerant Clouds. In 5th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 13), USENIX Association, San Jose, CA. [scholar]
-
[Perseus] Ruiming Lu, Erci Xu, Yiming Zhang, Fengyi Zhu, Zhaosheng Zhu, Mengtian Wang, Zongpeng Zhu, Guangtao Xue, Jiwu Shu, Minglu Li, and Jiesheng Wu. 2023. Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems. In 21st USENIX Conference on File and Storage Technologies (FAST 23), USENIX Association, Santa Clara, CA, 49–64. [scholar]
-
[Raft] Diego Ongaro and John Ousterhout. 2014. In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference (USENIX ATC'14), USENIX Association, USA, 305–320. [scholar]
-
[MultiPaxos] Roberto De Prisco, Butler Lampson, and Nancy Lynch. 1997. Revisiting the Paxos algorithm. In Distributed Algorithms, Springer Berlin Heidelberg, Berlin, Heidelberg, 111–125. [scholar]
-
[ZAB] Flavio P. Junqueira, Benjamin C. Reed, and Marco Serafini. 2011. Zab: High-performance broadcast for primary-backup systems. In Proceedings of the 2011 IEEE/IFIP 41st International Conference on Dependable Systems&Networks (DSN '11), IEEE Computer Society, USA, 245–256. [scholar]
-
[CockroachDB] Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis. 2020. CockroachDB: The Resilient Geo-Distributed SQL Database. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD '20), Association for Computing Machinery, New York, NY, USA, 1493–1509. [scholar]
-
[TiDB] Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. 2020. TiDB: a Raft-based HTAP database. Proc. VLDB Endow. 13, 12 (August 2020), 3072–3084. [scholar]
-
[Spanner] James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. 2012. Spanner: Google’s Globally-Distributed Database. In OSDI. [scholar]
-
[Paxos Made Live] Tushar Deepak Chandra, Robert Griesemer, and Joshua Redstone. 2007. Paxos Made Live - An Engineering Perspective (2006 Invited Talk). In Proceedings of the 26th Annual ACM Symposium on Principles of Distributed Computing. [scholar]
-
[Zookeeper] Patrick Hunt, Mahadev Konar, Flavio P. Junqueira, and Benjamin Reed. 2010. ZooKeeper: Wait-free Coordination for Internet-scale Systems. In 2010 USENIX Annual Technical Conference (USENIX ATC 10), USENIX Association. [scholar]
-
[Paxos Made Moderately Complex] Robbert Van Renesse and Deniz Altinbuken. 2015. Paxos Made Moderately Complex. ACM Comput. Surv. 47, 3 (February 2015). [scholar]
-
[MultiPaxos Made Complete] Zhiying Liang, Vahab Jabrayilov, Aleksey Charapko, and Abutalib Aghayev. 2024. MultiPaxos Made Complete. [scholar] [arXiv]
-
[Paxos vs Raft] Heidi Howard and Richard Mortier. 2020. Paxos vs Raft: have we reached consensus on distributed consensus? In Proceedings of the 7th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC '20), Association for Computing Machinery, New York, NY, USA. [scholar] [arXiv]
-
[Linearizable Quorum Reads] Aleksey Charapko, Ailidani Ailijiang, and Murat Demirbas. 2019. Linearizable Quorum Reads in Paxos. In 11th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 19), USENIX Association, Renton, WA. [scholar]
-
[Paxos Quorum Leases] Iulian Moraru, David G. Andersen, and Michael Kaminsky. 2014. Paxos Quorum Leases: Fast Reads Without Sacrificing Writes. In Proceedings of the ACM Symposium on Cloud Computing (SOCC '14), Association for Computing Machinery, New York, NY, USA, 1–13. [scholar]
-
[Consistent Follower Reads] Antonios Katsarakis, Vasilis Gavrielatos, Emmanouil Giortamis, Pramod Bhatotia, Aleksandar Dragojevic, Boris Grot, Vijay Nagarajan, and Panagiota Fatourou. 2025. The LAW Theorem: Local Reads and Linearizable Asynchronous Replication. Proceedings of the VLDB Endowment 18, 9 (May 2025), 2831–2845. [scholar]
-
[Ionia] Yi Xu, Henry Zhu, Prashant Pandey, Alex Conway, Rob Johnson, Aishwarya Ganesan, and Ramnatthan Alagappan. 2024. IONIA: High-Performance Replication for Modern Disk-based KV Stores. In 22nd USENIX Conference on File and Storage Technologies (FAST 24), USENIX Association, Santa Clara, CA, 225–241. [scholar]
-
[Raft’s Consistent Follower Reads] Diego Ongaro. 2014. Consensus: Bridging Theory and Practice. PhD thesis. Stanford University, Stanford, CA, USA. Section 6.4. [scholar]
-
[Pull-Based Consensus] Siyuan Zhou and Shuai Mu. 2021. Fault-Tolerant Replication with Pull-Based Consensus in MongoDB. In 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), USENIX Association, 687–703. [scholar]
-
[Scaling Replication] Aleksey Charapko, Ailidani Ailijiang, and Murat Demirbas. 2021. PigPaxos: Devouring the Communication Bottlenecks in Distributed Consensus. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD '21), Association for Computing Machinery, New York, NY, USA, 235–247. [scholar]
-
[Commutative Raft] Seo Jin Park and John Ousterhout. 2019. Exploiting Commutativity For Practical Fast Replication. In 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), USENIX Association, Boston, MA, 47–64. [scholar]
-
[Scalable But Wasteful] Venkata Swaroop Matte, Aleksey Charapko, and Abutalib Aghayev. 2021. Scalable but wasteful: Current state of replication in the cloud. In Proceedings of the 13th ACM Workshop on Hot Topics in Storage and File Systems, 42–49. [scholar]
See discussion of this page on Reddit, Hacker News, and Lobsters.